Meta: Less Wright, Meet Vadakkanchery, Saurabh Mishra, Ela Krepska, Hamid Shojanazeri, Pradeep Fernando
Crusoe: Ethan Petersen, Martin Cala, Chip Smith
PyTorch DCP (Distributed Checkpointing) has recently enabled new optimizations in asynchronous checkpointing to reduce GPU utilization drop by minimizing collective overhead and improving overall checkpointing efficiency.
Using Crusoe’s 2K H200 cluster, with TorchTitan and training a Llama3-70B, we were able to verify these new features deliver substantial speedups at 1856 GPU scale, reducing the background processing time for async DCP checkpoints from ~436 seconds to ~67 seconds.
This is roughly a 6.5x reduction in background checkpoint processing time, enabling even more total training time to proceed at full training throughput.
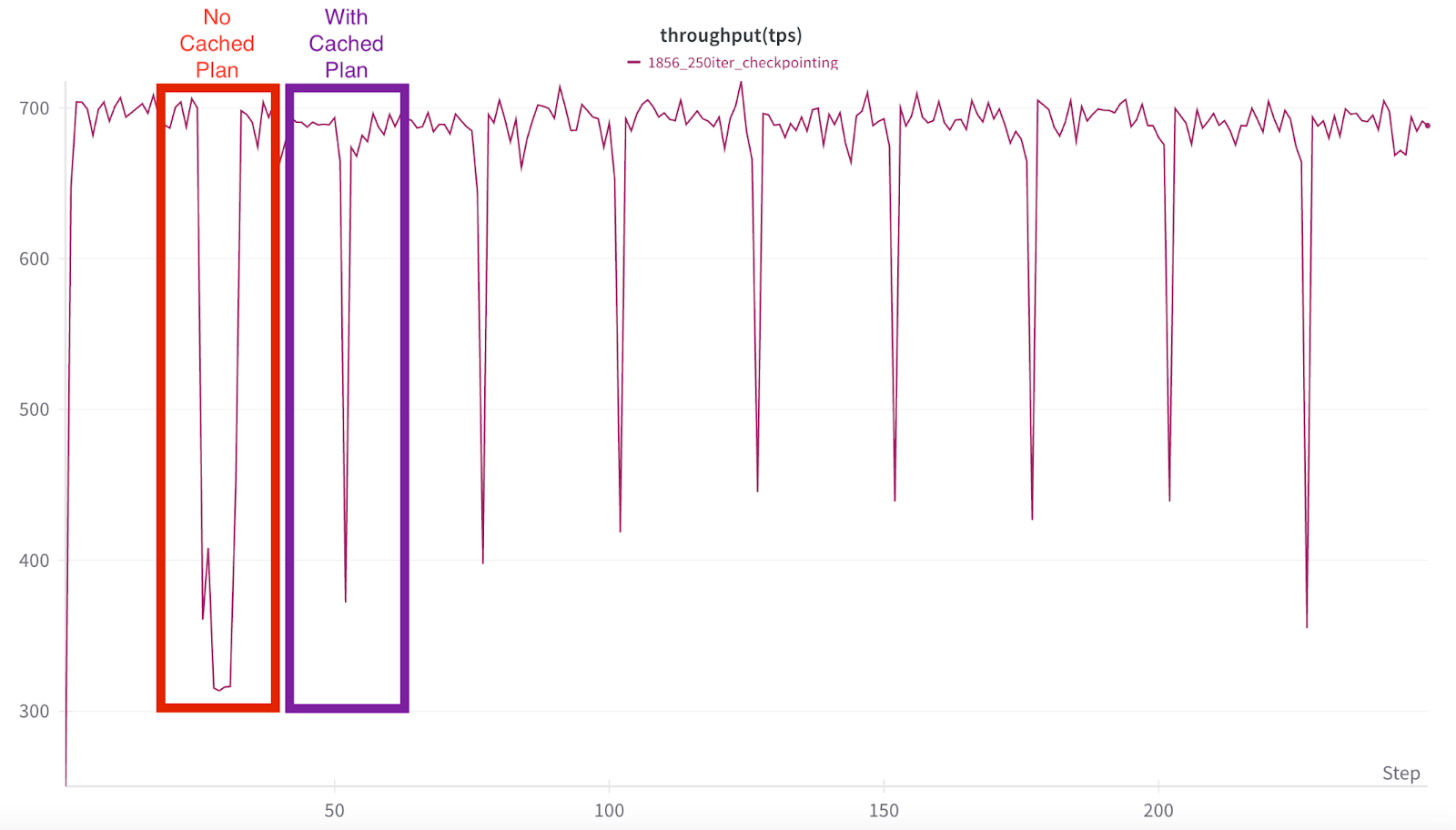
Fig 1: 1856 training run with high frequency checkpointing. The first checkpoint (drop down in tps) does not have a cached save plan, and the background processing takes far longer than the rest where the cached plan is used.
Background: What is Asynchronous Checkpointing?
In a standard checkpointing workflow, GPUs are blocked while the checkpointing data is offloaded from GPU to CPU and then written to storage. After the save to physical media is complete, training can resume.
Asynchronous checkpointing greatly reduces this downtime by enabling the actual saving to storage to be done via CPU threads, allowing GPU-based training to continue while the checkpoint data is being persisted in parallel. It is used primarily for intermediate/fault tolerant checkpoints as it unblocks the GPUs much faster compared to the synchronous checkpoints.
For example, in our large-scale experiment, GPU training was blocked for less than a second (.78 seconds at 1856 scale) while checkpoint data was moved from GPU to CPU (staging). At that point, GPU training immediately continues, which is a substantial training time improvement over traditional checkpointing. For reference, Async Checkpointing is covered in more detail here.
Challenges with Asynchronous Checkpointing
However, the background processing inherent in Asynchronous Checkpointing has additional challenges that result in a temporary reduction of training throughput while the storage phase is being completed. These are highlighted below.
GPU utilization drop from GIL contention:
The Global Interpreter Lock (GIL) in Python is a mechanism that prevents multiple native threads from executing Python bytecode at the same time. This lock is necessary mainly because CPython’s memory management is not thread-safe.
DCP currently uses background threads for metadata collectives and uploading to storage. Although these expensive steps are done asynchronously, it leads to contention for the GIL with the trainer threads. This causes the GPU utilization (QPS) to suffer significantly and also increases the e2e upload latency. For large-scale checkpoints, the overhead of the CPU parallel processing has a suppressive effect on net GPU training speed since CPUs also drive the training process via GPU kernel launches.
Please refer to the following figure from our experiments:
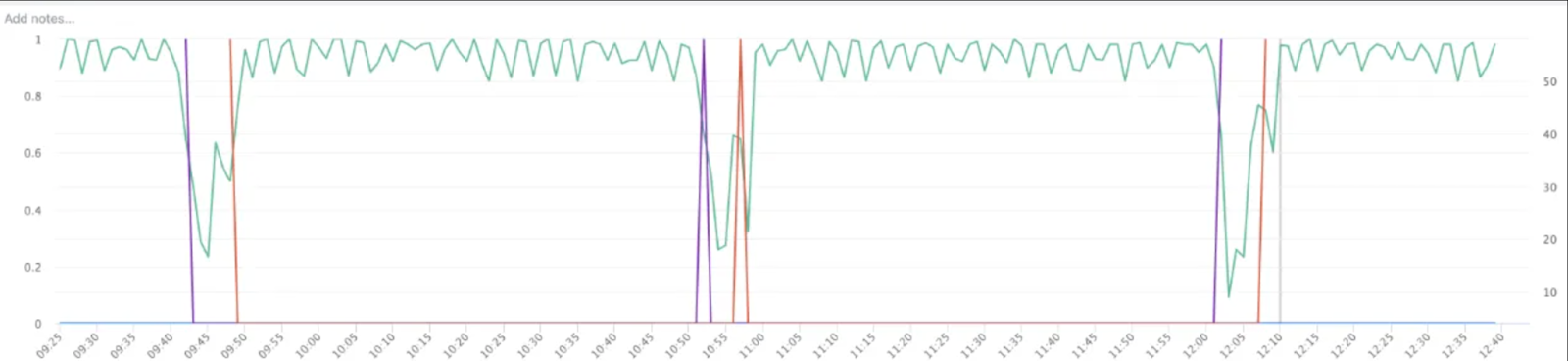
Fig 2: One can see a sustained drop in training QPS even after staging (i.e. blocking operation to trainer) is complete.
The first dip in Figure 2 (marked by the purple line) indicates that staging is complete, and training can continue. However, a second drop is evident (marked by the area between the purple and yellow lines) which is due to trainer thread and checkpointing threads contending for the Python GIL, leading to degraded training QPS until the checkpoint thread completes execution.
Collective communications cost:
DCP performs multiple collectives today for various reasons: dedupe, global metadata for the checkpoint, resharding, and distributed exception handling. Collectives are costly as these require network I/O and pickling/unpickling of the large metadata being sent across the GPU network. These collectives become extremely expensive as the job scale grows, leading to significantly higher e2e latency and potential for collective timeouts.
Solutions
Process based async checkpointing
DCP now supports async checkpoint save via a background process. This helps avoid the training QPS drop by eliminating the python GIL contention with the trainer threads. Please see Fig 2 for checkpointing via threads and Fig 3 for checkpointing via background process.
Caching of the save plans
DCP has a clear boundary between the planning and storage I/O steps. SavePlanner in DCP is a stateful component which acts as an access proxy to the state_dict. Planner manages save plans prepared by individual ranks, which carry metadata information necessary to do the write I/O. The planning step involves a collective operation to gather a comprehensive view of the checkpoint on the coordinator rank. The coordinator rank is responsible for de-duplicating parameters/weights to eliminate redundancies, validating the global plan to ensure accuracy and consistency, and creating the global metadata structs. This is followed by a scatter collective where the coordinator rank assigns I/O tasks to each rank. Any transformations done on the plans affect how the storage components finally write the data.
During the course of a training job, multiple checkpoints are saved. In the majority of these cases, only the checkpoint data changes between different save instances, and thus, the plan remains the same. This presented an opportunity for us to cache the plans, pay the planning cost only on the first save, and then amortize that cost across all the subsequent attempts. Only the updated plans (plans which changed in the next attempt) are sent via collective, thus reducing the collective overhead significantly.
Experiment Results
Set up: 1856 H200 GPUs, Llama3-70B, HSDP2 with TorchTitan
After deploying both the solutions above, the following are the key results:
- TPS drop has significantly narrowed, with a peak dip to 372 vs 315 tps, and for a greatly reduced time window (~67 seconds vs ~437 seconds). This time window is now mostly attributed to the blocking for CPU processing.
- Subsequent checkpoint save attempts also continue to be much faster due to very low overhead at the planning stage. E2E latency is thus improved by over 6.5x. This will allow our partners to increase the checkpointing frequency and reduce the lost training progress (i.e. wasted training time).
If you look at the very first downspike in Figure 1, this drawdown in GPU processing time takes training throughput from 700 down to 320 tps, and suppresses it for roughly 7 minutes (467 seconds). Once the CPUs have finished processing, training continues again at full speed.
Previously, this ~7 minute suppression would be repeated at every checkpoint. However, with the new process-based checkpointing feature, only the first checkpoint has the full drawdown time (mainly due to overhead from daemon process initialization), as all future checkpoints are executed via the background process, mitigating GIL contention with the trainer threads.
This is visually shown in all the subsequent checkpoints where the average MFU suppression time drops to just over a minute, reflected by the sharp spikes that almost immediately revert to full MFU throughput.
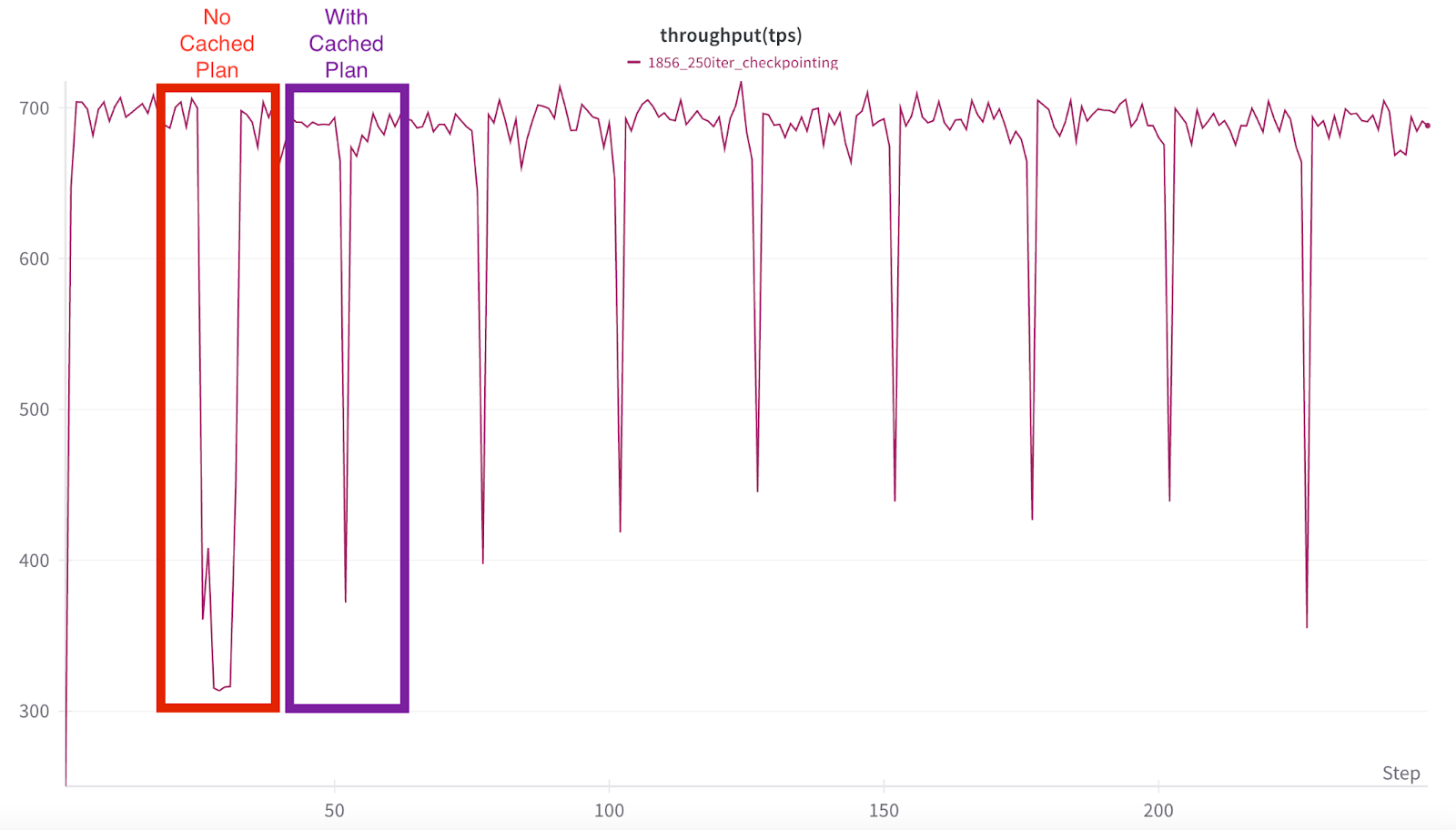
Fig 3: The red box shows the non-cached plan checkpoint, which also includes Checkpoint Background Init process overhead, while the purple box highlights the first checkpoint to run with the cached plan.
This means that even large-scale checkpointing, such as shown in Fig 2 at 1856 GPU scale, can be done with ~6x reduced training throughput impact. This enables Asynchronous DCP checkpointing to be run more frequently (thus better rollback protection) while enhancing total training throughput relative to previous Async Checkpointing overhead.
Using DCP’s cached checkpointing:
This feature is already available as part of the PyTorch nightly builds, and you can test out PyTorch’s Asynchronous DCP checkpointing directly in TorchTitan. Following are the instructions to enable these features:
- Process-based asynchronous checkpointing:
- Set the async_checkpointer_type to AsyncCheckpointerType.PROCESS in the async_save API. (file: pytorch/torch/distributed/checkpoint/state_dict_saver.py)
- Save plan caching:
- Set the enable_plan_caching flag to true in the DefaultSavePlanner. (file: pytorch/torch/distributed/checkpoint/default_planner.py)
Future work
DCP will be rolling out additional optimizations to further improve the checkpointing cost. Currently even though the save plans are cached, coordinator rank still prepares the metadata. For larger jobs and models with many tensors, this overhead is non-trivial. In the next iteration, DCP will eliminate the metadata overhead and improve the e2e latency further. DCP will also introduce additional optimizations, such as zero-overhead checkpointing, to enable efficient checkpointing in large-scale jobs.
Stay tuned!
